“Would you like to keep a tab behind the bar?” asked the bartender
The underwriter turned to the broker and enquired
“How many risks shall we be negotiating today Bruce?”
“Around 7 of them” replied the broker
“Then yes, please open a tab for me” said the underwriter to the bartender
Brokers play a pivotal role in placing large volumes of business in hands of Insurers on a daily basis. As a result the meeting between broker and underwriter becomes fundamental to the Insurance business. Many technologies have been proposed to enhance the meetings of broker and underwriter. Nevertheless, most the value propositions focussed on the aspect of collaborative tools that enable broker to virtually meet with underwriter over the Internet. Yet brokers and underwriters are always willing to meet each other, face-to-face, following a long and successful tradition, and utterly dislike any interfering technologies. Many of the online collaborative tools have failed to deliver value to both brokers and underwriters.
Unlike these traditional solutions, our business value proposition, which is the Mobile Broker Quest, is an innovative solution which does not attempt to act as a mediator in between the broker and the underwriter, but foster a catalyst to bring broker and underwriter together in a more efficient and prompt manner by focussing on the problem of broker appointment system.
Problem Statement
Traditionally, insurance companies provision a trading floor, with an appointment system, used by the brokers to book meetings with underwriters. One of the observed limitations of the existing appointment system is that the full capability of the service is constrained by the need for the broker to be physically present in the office. The waiting time is only known when the broker logs into system. Very often, the queue tends to be very too long, resulting to brokers leaving to meet other insurers or clients. The broker may or may not come back to the underwriter. This usually leads to an unsatisfactory customer experience and loss of potential business.There is an apparent problem in the current broker appointment system at a major insurance group. When one profiles the statistics, it reports a drop of 60% in appointment booked since 2005. Brokers are not using the system anymore, since the solution does not offer the value they need. In identifying a process which is no longer supporting the goals of the underwriting process, this paper explains how an innovative solution, Mobile Broker Quest (MBQ), has been articulated and designed by merging two robust methods together, namely, The Theory of Inventive Problem Solving (TRIZ) [Kap96] and Testable Architecture (TA) [Tal04][Yang06] into a Blended Modelling Approach for innovation.
Blended Modelling Approach
There are two acceptable attitudes of modelling, namely deductive modelling and inductive modelling [Oud02]. In the problem realm of deductive modelling, a model is an a priori representation of observed phenomena from reality wherein the process is to assume the model to be true upfront and the representation often becomes a structure which can be cloned or reproduced. These structures becomes moulds and knowledge from similar phenomenon observed in one’s problem domain can be “poured into these mould” which will lead to models of the problem definition. In the realm of inductive modelling, a model is an a posteriori representation of observed phenomena from reality and we understand that the reality and/or observation may change. Designers attempt to map the observations to a formal system so that these formalisms can be tested and simulated against the observations. Should the formal system be proven to be true, then a model exists, i.e. it has been induced, otherwise there is no existence of a model at this time.
In order to manage the variations and unknowns of an innovation process model, we are required to use both the inductive and deductive modelling techniques. This potentially adds scientific rigour to remove ambiguity in requirements, resolve design defects, increasing the power of modelling. However to join both discipline requires a robust framework. Our proposed blended modelling approach merges the 2 attitudes of modelling together using a formal and mathematical framework called Testable Architecture [Tal09].
The Mind Model of the AS – IS Process
We formulated a mind model by observing and learning from the customer problem domain. The point of focus was the trading floor at a global insurance group in London. Brokers need to be physically in the trading floor in order to enter the waiting line system by interacting with a touch screen interface, provisioning his/her credentials.
Quality Modelling
The House of Quality

The Implementation of the Theory of Inventive Problem Solving (TRIZ)
TRIZ is interdisciplinary and closely related to logic, psychology, history of technology and philosophy of science. The two basic principles in TRIZ 1) “Somebody, someplace, has already solved your problem or one similar to it. Creativity means finding that solution and adapting it to the current problem;” and 2) “Don't accept compromises. Eliminate them”. The main concept applied by Altshuller, the inventor of TRIZ, in developing the 40 principles is that contradictions (or trade-offs) are the constraints that inventions seek to resolve. Inventive solutions do not seek equilibrium along the trade-off, but “dissolve” the contradiction. Inventions are intended to solve problems which are fundamentally “the difference between what we have and what we want” (De Bono). The problems in turn are derived from contradictions. Any invention is therefore intended to “resolve” or “dissolve” these contradiction. From these premises Altshuller developed the 40 principles and the “Matrix of Contradictions”, see Figure 3.
As observed, TRIZ does not provide the breakthrough idea, but spells out the principles to guide designers / innovators in catalysing the process of idea generation, i.e. the seed idea.
The Seed Idea
In translating the principles as prescribed by TRIZ, designed natively for the manufacturing domain, into the problematic of business process and software enablement, the following principles guides us to produce the seed idea. The latter comes from a mixture of understanding the pain points, potential enhancements of business processes creativity and the dissolution of contradictions. There is no process for creativity but there are indicators that can help to build an environment that fosters and directs creativity. The translation process harvested the following:The seed idea is evaluated and rationalized in order to invent the user requirements of the solution. The process of translating the seed idea into requirement consist of fact-finding, identifying constraints as well as expanding information. This involves the analysis of the as-is model (see Figure 1) to understand the problem by delineating and refining constraints. Classically, in the problematic of software engineering, requirements are classified into two classes which are functional and non functional requirement [Boeh76]. However, it has been argued that user requirements have to be classified into their distinct styles which are more profound than the conventional two classes. The process of classification will provide the directives to which type of modelling tools, including inductive modelling tools, should be employed to the different styles of requirement. This is typically to address the approach of blended modelling which is supported by Testable Architecture. Typically, there are four types of the requirement styles which are 1) the data style, 2) the functional and logical style, 3) the communication and behavioural style and 4) the quality styles.

Table 1 Understanding the character of requirement
The TO – BE MODEL of the Mobile Broker Quest

Figure 4 To- Be model of the Mobile Broker Quest
The Application of Testable Architecture
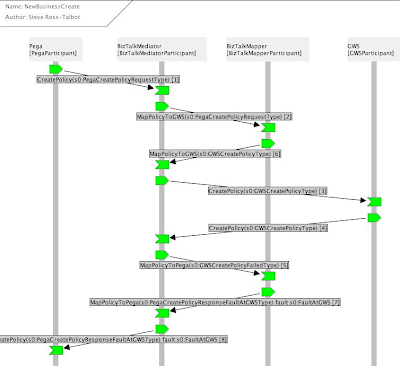
A dynamic model is based on formal methods, subsequently enabling designer to type check and simulate the proposed model against the refined requirements and the quality model. This part of the modelling discipline is inductive and primarily it allows design and requirement defects to be found and fixed prior to coding. Testable Architecture (TA) is the core engine of the innovation process model and key to the success of the proposed idea, i.e. the Mobile Broker Quest. TA is a methodology that abstracts the complexity of formal methods, pi calculus [Miln80a] [Miln80b] [Miln93], Petri nets [Pet62] and Z Notation to provide a “run time simulation engine” and type check compiler to dynamic models. It fundamentally has the capability of blending structural modelling with inductive modelling, acting as a compiler to design and models. As we journey through the process of building a dynamic representation of the requirement that describe the phenomenon of two participants booking appointments, we are able to exercise the dynamic model to verify and validate against two key question: 1) Is the model representing the right thing?; and 2) Is the model representing the thing right?
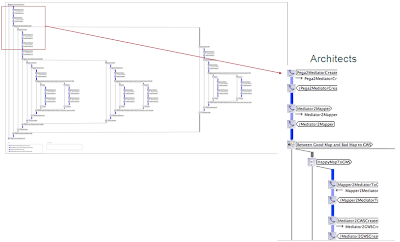
Figure 5 The Meta Model of the Mechanics of CPN
Formal and Dynamic Modelling

Figure 6 CPN Model of the Waiting Line
Observations In Figure 8, the graph reports on the time taken for a large sample of appointment requests to leave the system. The objective is to estimate the number of brokers waiting for more than n minutes (where n is defined by the SLA) that exist given an input burst. The graph shows the period of time a number of brokers take to meet an underwriter, e.g. over hundred appointment requests, a broker take 12 minutes. Hence using such analysis, a threshold can be established to identify those brokers that have a probability of waiting for too long. Figure 8 Waiting Time of Broker
Figure 7 Waiting Line Dynamics of Mobile Broker Quest
In order to reduce the number of variables in the experiments, we employed the Taguchi Method of Design of Experiment (DoE), used to determine the relationship between the different factors (Xs) affecting a process and the output of that process (Y). In the defined quality model we are seeking the fundamental SLAs of the MBQ which is to increase the number of appointments in a day to increase revenue in new business. So the function exercised into DoE is as follows:


The Solution Architecture
As the solution architecture is formulated, the continuity of the innovation life cycle follows the path of the classical Software Development Life Cycle for coding and testing which ideally fits into the constraints of the Spiral Model.
Conclusion
Reference
[Gar93] Garlan D, Shaw M, “An Introduction to Software Architecture, in Advances in Software Engineering and Knowledge Engineering” Vol 1, ed. Ambriola and Tortora World scientific Publishing Co., 1993
[Jeff91] Jeffrey J M, “Using Petri nets to introduce operating system concepts”, Paper presented at the SIGCSE Technical Symposium on Computer Science Education, San Antonio, USA, 7-8 March 1991
[Kap96] Kaplan S, “An Introduction to TRIZ – The Russian Theory of Invention Problem Solving”, Ideation Intl Inc, 1996
[Miln80a] Milner R, “A Calculus of Communicating Systems”, Lecture Notes in Computer Science, volume 92, Springer-Verlag, 1980
[Miln80b] Milner R, “A Calculus of Communicating Systems”, Lecture Notes in Computer Science, volume 92, Springer-Verlag, 1980
[Miln93] Milner R, “The Polyadic pi-Calculus: A Tutorial”, L. Hamer, W. Brauer and H. Schwichtenberg, editors, Logic and Algebra of Specification, Springer-Verlag, 1993
[Oud02] Oudrhiri R, “Une approche de l’évolution des systèmes,- application aux systèmes d’information”, ed.Vuibert, 2002
[Pet62] Petri C A, "Kommunikation mit Automaten", PhD thesis, Institut f¨ur instrumentelle Mathematik, Bonn, 1962
[Shaw01] Shaw M, “The coming-of-age of software architecture research”, in Proceedings of ICSE, pp. 656–664, Carnegie Mellon University, 2001
[Tal04] Ross–Talbot S, “Web Service Choreography and Process Algebra”, W3C Consortium, 2004
[Tal09] Ross-Talbot S, “Savara - from Art to Engineering: It’s all in the description”, University of Leicester, Computer Science Seminar, 2009
[Yang06] Yang H et al, “Type Checking Choreography Description Language”, Lecture Notes in Computer Science Springer-Berlin / Heidelberg, Peking University, 2006
[Yoji90] Akao Y, “Quality Function Deployment: Integrating Customer Requirements into Product Design” (Translated by Glenn H. Mazur), Productivity Press, 1990